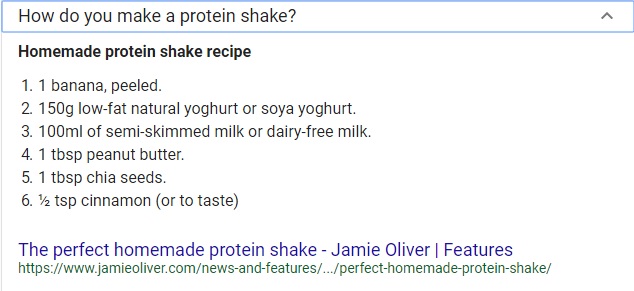
Source: Union of Concerned Scientists
The devastation caused by Hurricane Maria is still being revealed nearly a year and a half after the storm ripped through the island. Of course, anyone who has lived through a disaster like this will tell you that the island will probably never recover. Not to mention that the loss of life can never be replaced. With that being said, any community (or island) must find the courage to recover and re-establish life as it were if possible.
Under normal conditions, agencies such as FEMA (Federal Emergency Management Agency) would provide sufficient funds to help the island start the journey toward recovery. Unfortunately, we do not live in normal conditions at the current moment under the current administration. Funding agencies are being stressed beyond reach for existing funds and when this occurs, areas like scientific research usually suffer the most.
How Did Maria Impact Science?
At the very least, the lightest impact (which actually may not be true due to PTSD), the lab members may undergo treatment to make sure that there are no residual medical issues after a storm has hit the island. Of course, if you have no laboratory staff: graduate students, undergraduate students, postdoc's, professional researchers -- then you have no lab. Meaning, all the best equipment can occupy the lab, but without scientists to run and monitor the instruments, then there is no lab.
The second critical component of any scientific laboratory are the scientific instruments and infrastructure in which these along with the supplies (beakers, tubing, cell cultures, glove boxes, etc.) needed to conduct good/sound science. This is sometimes the perceived most critical component of any scientific laboratory. Although, I would argue that the scientists which occupy any laboratory are the most critical components to any scientific instruments. I have yet to see any scientific instrument just start collecting data by itself without any scientist's intervention/initiation.
A recent article in 'The Scientist' titled "Science in Puerto Rico Still Recovering After Hurricane Maria" details some of the disastrous consequences to a scientific laboratory after a storm of a magnitude such as Hurricane Maria. The human damage alone can be irreplaceable not to mention the buildings and local municipal utility grid. And when the destruction to the infrastructure is considered, parameters such as mold and water damage can set a laboratory recovery back several months to years:
Giray’s lab is among 14 or so in the Julio Garcia Diaz biology building, which was among those severely damaged, particularly as it was already undergoing roof repairs when the storm hit. Water seeped in through the roof and windows, damaging costly research equipment, furniture, and lab materials. Toxic mold thrived in the moist, hot climate, creating hazardous conditions that made the building uninhabitable. Power outages cut off researchers’ freezers and fridges, destroying precious genetic and tissue samples for good. The damages are estimated to range from $250,000 up to $2.5 million dollars per lab in that building, says Giray, a behavioral biologist whose main focus is honeybees.
Even more important are samples which are collected outside of the laboratory or purchased for several thousand dollars which are sensitive to temperature/humidity/vibrational fluctuations:
Some of the casualties from the hurricane are less easy to restore: “Collections take much longer time and may never be replaced,” says Giray’s colleague Riccardo Papa, who lost almost all of his DNA samples documenting the diversity of butterflies across South America when his lab’s –80 °C freezer lost electricity. Papa, an evolutionary biologist, didn’t have a lab again until a week ago, and until recently has been meeting with his students and postdocs at coffee shops or places around campus to discuss research. He has been able to do some experiments and genetic analyses in another building. Repairs are still underway for the damaged insectary, in which his team raises butterflies.
Research must go on. With or without the infrastructure. Here in California, after the Northridge Earthquake in 1994, FEMA set up temporary 'mobile homes' to serve as both classrooms and temporary offices along with laboratories in certain circumstances. To hear that 'group meetings' were still being held at coffee shops is a testament to the pace of recovery. In a majority of cases after a disaster, classroom recovery comes first, then eventually research laboratories. Although, it is worth remembering that each research laboratory group is made up of students and research professors who take years (applying for individual grants/writing publications) to acquire the appropriate funding to purchase research scientific instrumentation. Therefore, to put a price on the total loss in the event of a disaster like Hurricane Maria proves extremely difficult.
The total cost to a researcher is really unknowable for years to come. Some researchers never recover and decide to shut down their laboratories after such a storm. Which leaves current graduate students without an end in sight to their degrees (M.A. and PhD). Additionally, staff (professional researchers) might quickly find themselves out of work and have to leave regions like Puerto Rico and find work elsewhere. Which means transplanting their families and children's education to a different geographical location. The cost can be severe not just to the researcher themselves.
More can be written in future articles on this theme of disasters and research laboratories. Either together or separately. The total cost to a geographical location from a disaster such as Hurricane Maria can only be estimated at the beginning (a very rough approximation). The price tag evolves over time with the disbursement of emergency funds by organizations such as FEMA along with other federal organizations or the Congress. The terrible destruction to a scientific institution is terrible to say the least. Restoring science should be a high priority among others on the island of Puerto Rico.
Related Blog Posts:
Parameters: What Research/Science Is Affected During A Government Shutdown?
What does a Government Shutdown look like?
What is the difference between General Anxiety Disorder and Trump Anxiety Disorder?
Dimensional Analysis Of Statistics And Large Numbers - Index Of Blog Posts
Science Topics, Thoughts, and Parameters Regarding Science, Politics, And The Environment!
Puerto Rico Aid Should Not Be A Partisan (Political) Issue
Natural Disasters Hit, What Happens to School Students?
Parameters: What Research/Science Is Affected During A Government Shutdown?
What does a Government Shutdown look like?
What is the difference between General Anxiety Disorder and Trump Anxiety Disorder?
Dimensional Analysis Of Statistics And Large Numbers - Index Of Blog Posts
Science Topics, Thoughts, and Parameters Regarding Science, Politics, And The Environment!
Puerto Rico Aid Should Not Be A Partisan (Political) Issue
Natural Disasters Hit, What Happens to School Students?